SQL 通配符
通配符可用于替代字符串中的任何其他字符。
SQL 通配符
在 SQL 中,通配符与 SQL LIKE 操作符一起使用。
SQL 通配符用于搜索表中的数据。
在 SQL 中,可使用以下通配符:
| 通配符 | 描述 |
|---|---|
| % | 替代 0 个或多个字符 |
| _ | 替代一个字符 |
| [charlist] | 字符列中的任何单一字符 |
| [^charlist] 或 [!charlist] |
不在字符列中的任何单一字符 |
演示数据库
在本教程中,我们将使用 RUNCODEX 样本数据库。
下面是选自 "Websites" 表的数据:
+----+--------------+---------------------------+-------+---------+ | id | name | url | alexa | country | +----+--------------+---------------------------+-------+---------+ | 1 | Google | https://www.google.cm/ | 1 | USA | | 2 | 淘宝 | https://www.taobao.com/ | 13 | CN | | 3 | 码农教程 | http://www.runcodex.com/ | 4689 | CN | | 4 | 微博 | http://weibo.com/ | 20 | CN | | 5 | Facebook | https://www.facebook.com/ | 3 | USA | | 7 | stackoverflow | http://stackoverflow.com/ | 0 | IND | +----+---------------+---------------------------+-------+---------+
使用 SQL % 通配符
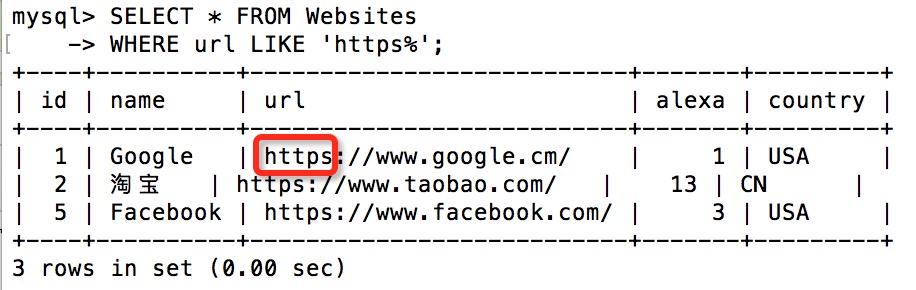
下面的 SQL 语句选取 url 以字母 "https" 开始的所有网站:
实例
SELECT * FROM Websites
WHERE url LIKE 'https%';
WHERE url LIKE 'https%';
执行输出结果:
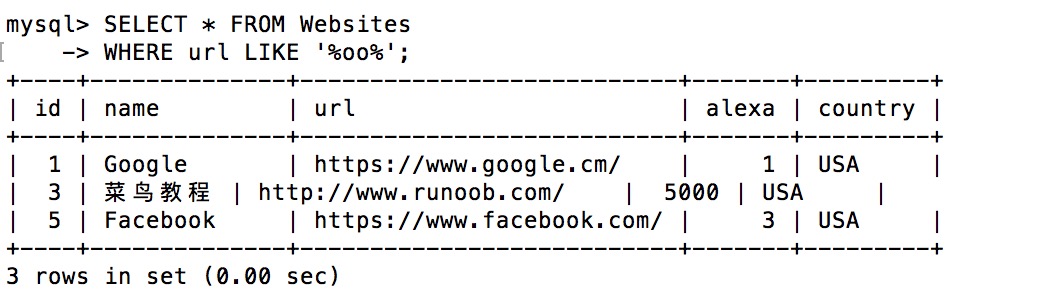
下面的 SQL 语句选取 url 包含模式 "oo" 的所有网站:
实例
SELECT * FROM Websites
WHERE url LIKE '%oo%';
WHERE url LIKE '%oo%';
执行输出结果:
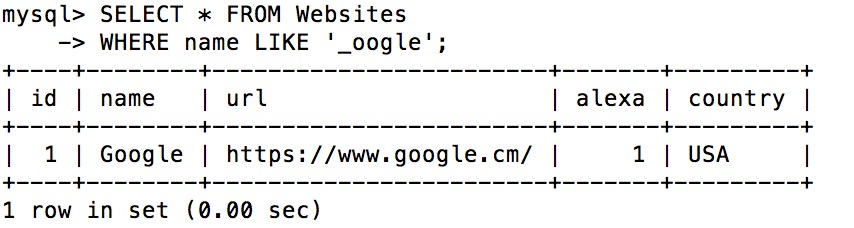
使用 SQL _ 通配符
下面的 SQL 语句选取 name 以一个任意字符开始,然后是 "oogle" 的所有客户:
实例
SELECT * FROM Websites
WHERE name LIKE '_oogle';
WHERE name LIKE '_oogle';
执行输出结果:
下面的 SQL 语句选取 name 以 "G" 开始,然后是一个任意字符,然后是 "o",然后是一个任意字符,然后是 "le" 的所有网站:
实例
SELECT * FROM Websites
WHERE name LIKE 'G_o_le';
WHERE name LIKE 'G_o_le';
执行输出结果:
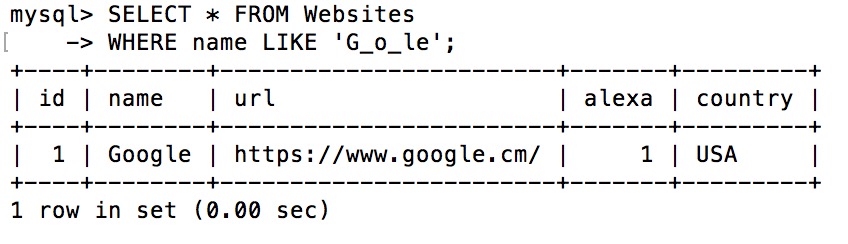
使用 SQL [charlist] 通配符
MySQL 中使用 REGEXP 或 NOT REGEXP 运算符 (或 RLIKE 和 NOT RLIKE) 来操作正则表达式。
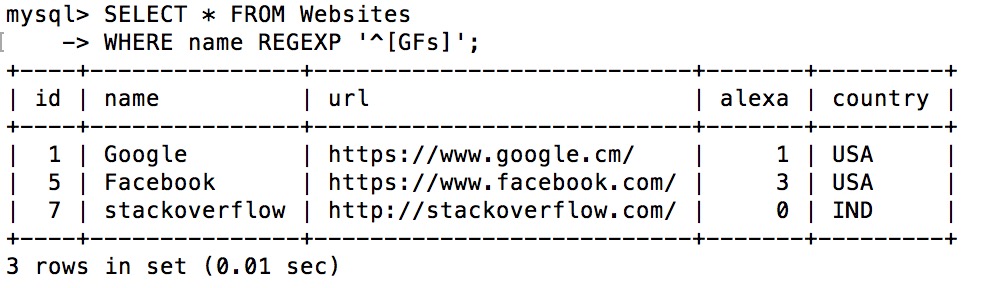
下面的 SQL 语句选取 name 以 "G"、"F" 或 "s" 开始的所有网站:
实例
SELECT * FROM Websites
WHERE name REGEXP '^[GFs]';
WHERE name REGEXP '^[GFs]';
执行输出结果:
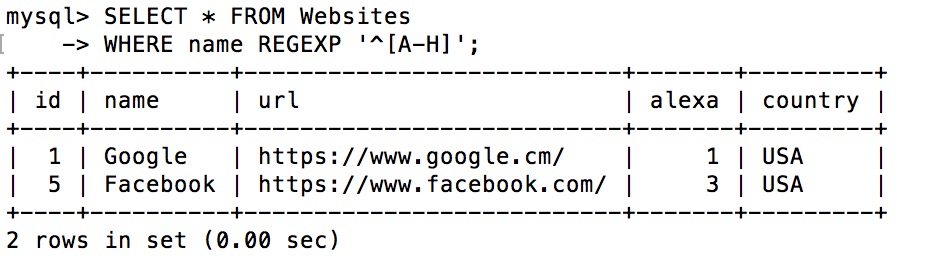
下面的 SQL 语句选取 name 以 A 到 H 字母开头的网站:
实例
SELECT * FROM Websites
WHERE name REGEXP '^[A-H]';
WHERE name REGEXP '^[A-H]';
执行输出结果:
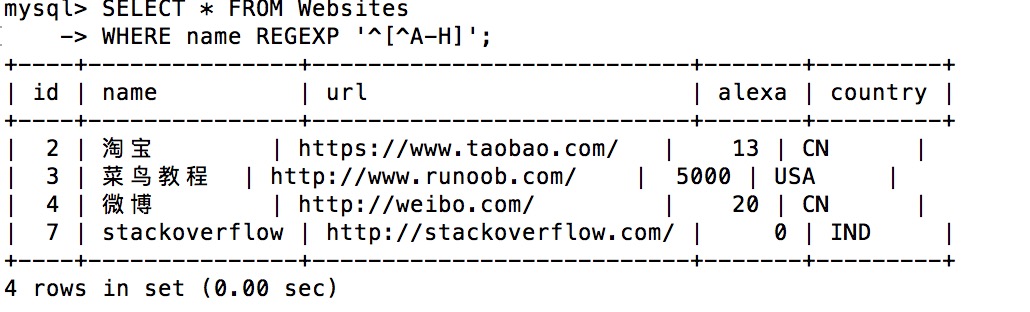
下面的 SQL 语句选取 name 不以 A 到 H 字母开头的网站:
实例
SELECT * FROM Websites
WHERE name REGEXP '^[^A-H]';
WHERE name REGEXP '^[^A-H]';
执行输出结果:





番茄土豆
799***193@qq.com
参考地址
首先说下LIKE命令都涉及到的通配符:
% 替代一个或多个字符
_ 仅替代一个字符
[charlist] 字符列中的任何单一字符
[^charlist]或者[!charlist] 不在字符列中的任何单一字符
其中搭配以上通配符可以让LIKE命令实现多种技巧:
1、LIKE'Mc%' 将搜索以字母 Mc 开头的所有字符串(如 McBadden)。
2、LIKE'%inger' 将搜索以字母 inger 结尾的所有字符串(如 Ringer、Stringer)。
3、LIKE'%en%' 将搜索在任何位置包含字母 en 的所有字符串(如 Bennet、Green、McBadden)。
4、LIKE'_heryl' 将搜索以字母 heryl 结尾的所有六个字母的名称(如 Cheryl、Sheryl)。
5、LIKE'[CK]ars[eo]n' 将搜索下列字符串:Carsen、Karsen、Carson 和 Karson(如 Carson)。
6、LIKE'[M-Z]inger' 将搜索以字符串 inger 结尾、以从 M 到 Z 的任何单个字母开头的所有名称(如 Ringer)。
7、LIKE'M[^c]%' 将搜索以字母 M 开头,并且第二个字母不是 c 的所有名称(如MacFeather)。
番茄土豆
799***193@qq.com
参考地址
白菜
min***eyiyi@gmail.ccom
SQL 中,通配符与 SQL LIKE 操作符一起使用。
不过,MySQL 、SQLite 只支持 % 和 _ 通配符,不支持 [^charlist] 或 [!charlist] 通配符( MS Access 支持,微软 office 对通配符一直支持良好,但微软有时候的通配符不支持 %,而是 *,具体看对应软件说明)。通配符和正则不是一回事。
MySQL 和 SQLite 会把 like '[xxx]yyy' 的中括号当成普通字符,而不是通配符。
比如:
将查出 city 为 [B]eijing 的行,而不是 city 为 beijing 的行。
MySQL 中要完成 [^charlist] 或 [!charlist] 通配符的查询效果,需要通过正则表达式来完成。
select * from persons WHERE City REGEXP '[b]eijing' SQLite不支持Regexp正则方法。白菜
min***eyiyi@gmail.ccom
julian
154***05@qq.com
参考地址
SQL:REGEXP
作为一个更为复杂的示例,正则表达式 B[an]*s 匹配下述字符串中的任何一个:Bananas,Baaaaas,Bs,以及以 B开始、以 s 结束、并在其中包含任意数目 a 或 n 字符的任何其他字符串。
以下是可用于随 REGEXP 操作符的表的模式。
应用示例,查找用户表中Email格式错误的用户记录:
SELECT * FROM users WHERE email NOT REGEXP '^[A-Z0-9._%-]+@[A-Z0-9.-]+.[A-Z]{2,4}$'MySQL 数据库中正则表达式的语法,主要包括各种符号的含义。
(^)字符
匹配字符串的开始位置,如 ^a 表示以字母 a 开头的字符串。
查询 xxxyyy 字符串中是否以 xx 开头,结果值为 1,表示值为 true,满足条件。
($)字符
匹配字符串的结束位置,如 X^ 表示以字母 X 结尾的字符串。
(.)字符
这个字符就是英文下的点,它匹配任何一个字符,包括回车、换行等。
(*)字符
星号匹配 0 个或多个字符,在它之前必须有内容。如:
这个 SQL 语句,正则匹配为 true。
(+)字符
加号匹配 1 个或多个字符,在它之前也必须有内容。加号跟星号的用法类似,只是星号允许出现 0 次,加号则必须至少出现一次。
(?)字符
问号匹配 0 次或 1 次。
实例:
现在根据上面的表,可以装置各种不同类型的 SQL 查询以满足要求。在这里列出一些理解。考虑我们有一个表为 person_tbl 和有一个字段名为名称:
查询找到所有的名字以 st 开头:
查询找到所有的名字以 ok 结尾
查询找到所有的名字包函 mar 的字符串:
查询找到所有名称以元音开始和 ok 结束的:
一个正则表达式中的可以使用以下保留字 :
^
所匹配的字符串以后面的字符串开头:
$
所匹配的字符串以前面的字符串结尾:
.
匹配任何字符(包括新行)
a*
匹配任意多个a(包括空串)
a+
匹配任意多个a(不包括空串)
a?
匹配一个或零个 a
de|abc
匹配 de 或 abc
(abc)*
匹配任意多个abc(包括空串)
{1} 、{2,3}
这是一个更全面的方法,它可以实现前面好几种保留字的功能
a* 可以写成 a{0,}
a+ 可以写成 a{1,}
a? 可以写成 a{0,1}
在 {} 内只有一个整型参数i,表示字符只能出现i次;在 {} 内有一个整型参数 i,后面跟一个 ,,表示字符可以出现 i 次或 i 次以上;在{}内只有一个整型参数 i,后面跟一个 ,,再跟一个整型参数 j,表示字符只能出现 i 次以上,j 次以下(包括 i 次和 j 次)。其中的整型参数必须大于等于 0,小于等于 RE_DUP_MAX(默认是 255)。 如果有两个参数,第二个必须大于等于第一个。
[a-dX]
匹配 “a”、“b”、“c”、“d” 或 “X”。
[^a-dX]
匹配除 “a”、“b”、“c”、“d”、“X” 以外的任何字符。
[、] 必须成对使用
julian
154***05@qq.com
参考地址
春姐
985***322@qq.com
参考地址
SQL:REGEXP
作为一个更为复杂的示例,正则表达式 B[an]*s 匹配下述字符串中的任何一个:Bananas,Baaaaas,Bs,以及以 B 开始,以 s 结束、并在其中包含任意数目 a 或 n 字符的任何其他字符串。以下是可用于随 REGEXP 操作符的表的模式。
应用示例,查找用户表中 Email 格式错误的用户记录:
SELECT * FROM users WHERE email NOT REGEXP '^[A-Z0-9._%-]+@[A-Z0-9.-]+.[A-Z]{2,4}$'MySQL 数据库中正则表达式的语法,主要包括各种符号的含义。
^ 字符
匹配字符串的开始位置,如 ^a 表示以字母 a 开头的字符串。
查询 xxxyyy 字符串中是否以 xx 开头,结果值为 1,表示值为 true,满足条件。
$ 字符
匹配字符串的结束位置,如 X$ 表示以字母 X 结尾的字符串。
. 字符
这个字符就是英文下的点,它匹配任何一个字符,包括回车、换行等。
* 字符
星号匹配 0 个或多个字符,在它之前必须有内容。如:
这个 SQL 语句,正则匹配为 true。
+ 字符
加号匹配 1 个或多个字符,在它之前也必须有内容。加号跟星号的用法类似,只是星号允许出现 0 次,加号则必须至少出现一次。
? 字符
问号匹配 0 次或 1 次。
实例:
现在根据上面的表,可以装置各种不同类型的 SQL 查询以满足要求。在这里列出一些理解。考虑我们有一个表 为person_tbl 和有一个字段名为 name。
查询找到所有的名字以 st 开头:
查询找到所有的名字以 ok 结尾:
查询找到所有的名字包函 mar 的字符串:
查询找到所有名称以元音开始和 ok 结束的:一个正则表达式中的可以使用以下保留字。
^
所匹配的字符串以后面的字符串开头:
$
所匹配的字符串以前面的字符串结尾:
.
匹配任何字符(包括新行):
a*
匹配任意多个 a(包括空串):
a+
匹配任意多个 a(不包括空串):
a?
匹配一个或零个 a:
de|abc
匹配 de 或 abc:
(abc)*
匹配任意多个abc(包括空串):
{1}
{2,3}
这是一个更全面的方法,它可以实现前面好几种保留字的功能。
a* 可以写成 a{0,}。
a+ 可以写成 a{1,}。
a? 可以写成 a{0,1}。
在 {} 内只有一个整型参数 i,表示字符只能出现 i 次;在 {} 内有一个整型参数 i,后面跟一个 ,,表示字符可以出现 i 次或 i 次以上;在 {} 内只有一个整型参数 i,后面跟一个 ,,再跟一个整型参数 j, 表示字符只能出现 i 次以上,j 次以下(包括 i 次和 j 次)。其中的整型参数必须大于等于 0,小于等于 RE_DUP_MAX(默认是 255)。 如果有两个参数,第二个必须大于等于第一个。
[a-dX] 匹配 “a”、“b”、“c”、“d” 或 “X”。
[^a-dX] 匹配除 “a”、“b”、“c”、“d”、“X” 以外的任何字符。
“[”、“]” 必须成对使用:
春姐
985***322@qq.com
参考地址